NLP
[NLP #2] Word2Vec & Fasttext & Doc2Vec
Dobby1234
2024. 2. 5. 16:39
Embedding: Word2Vec (2013)
2. 주변 맥락으로 단어를 표현해 보자

- 주변 단어가 비슷한 단어들은 배열이 유사해 질 것. (즉, 유사 단어끼리 유사한 배열을 가질 수 있다.)

- 배열은 단어의 주변 맥락을 표현한다. 이를 더하고 뺌으로써 단어 사이의 관계를 파악할 수 있다.

★ 단점
- 동음이의어를 구분할 수 없다.
- 우리는 말을 보며 말을 나눴다 → 말을 이라는 단어의 배열에는 horse와 mouth의 맥락이 혼재된다.
- 전혀 관계 없더라도 주변 단어가 비슷하면 비슷하게 임베딩 된다.
- 오늘 __ 갔다 → '학교, 서울, 그곳에' 등 무관한 단어가 비슷하게 표현된다.
- 단어 단위로 학습하다 보니 문장 단위의 맥락을 이해하지 못한다.
- 어제 식당에서 친구를 만났다. 거기서 함께 밥을 먹었다. → 거기서가 무엇을 가리키는지 알지 못한다.
▶ 문장 단위의 문맥을 고려할 필요성이 생긴다.
Word2Vec의 변형

Embedding: Fasttext

- 단어를 문자 단위로 쪼개서, 각 조각마다 word2vec을 수행
- 중간에 오타가 있어도 합리적인 결과를 얻을 수 있음

- 한글의 경우 자모로 쪼개서 할 경우 성능이 향상됨
Sentence embedding: Doc2vec (2014)
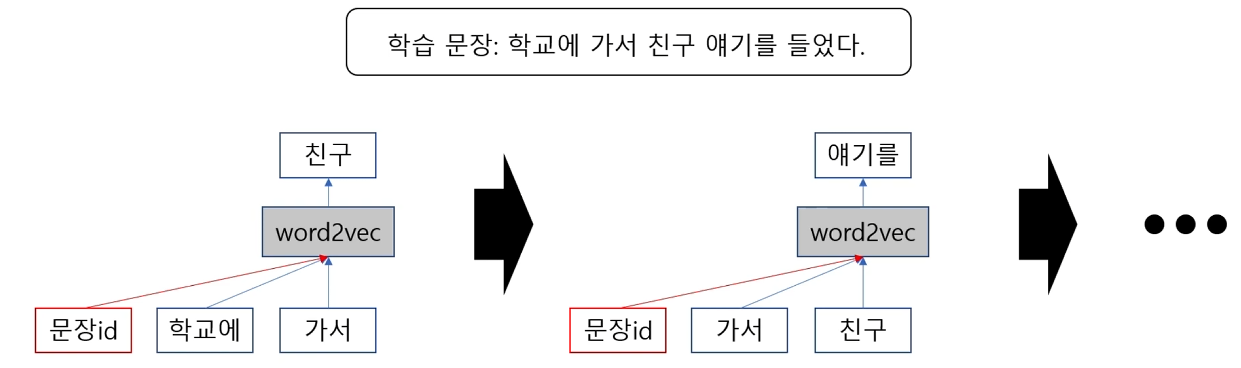
- 문장마다 id를 부여하고, 해당 문장을 word2vec과 유사한 형태로 학습하며 문장id의 배열을 업데이트 한다.
- 학습이 끝나고 나면 각 문장의 id마다 배열이 생성되며, 비슷한 단어로 이루어진 문장은 비슷한 배열을 갖는다.