NLP
[NLP #3] Transformers
Dobby1234
2024. 2. 5. 19:38
Embedding: Transformer (2017)
3. 문장의 맥락을 파악해보자

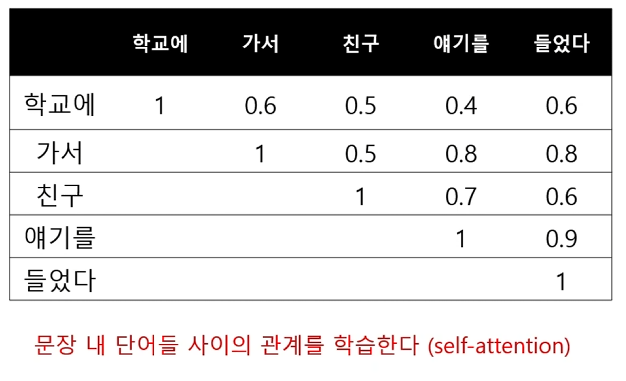
- 문장 내 단어들의 관계 특성, 문장 내 중요한 단어를 고려한 배열을 생성하는데, 배열 생성을 조금씩 다른 방식으로 수십 번을 수행한 후 이를 합하여 문장을 배열로 나타낸다.
- 보통 위 과정을 1회에 끝내지 않고, 배열 생성 방식 자체를 또 수십 번 반복하여 최종적인 문장 배열을 생성한다.
- 2017년 이후 가장 좋은 성능을 내는 언어모델은 모두 이 transformer를 기반으로 하고 있다.



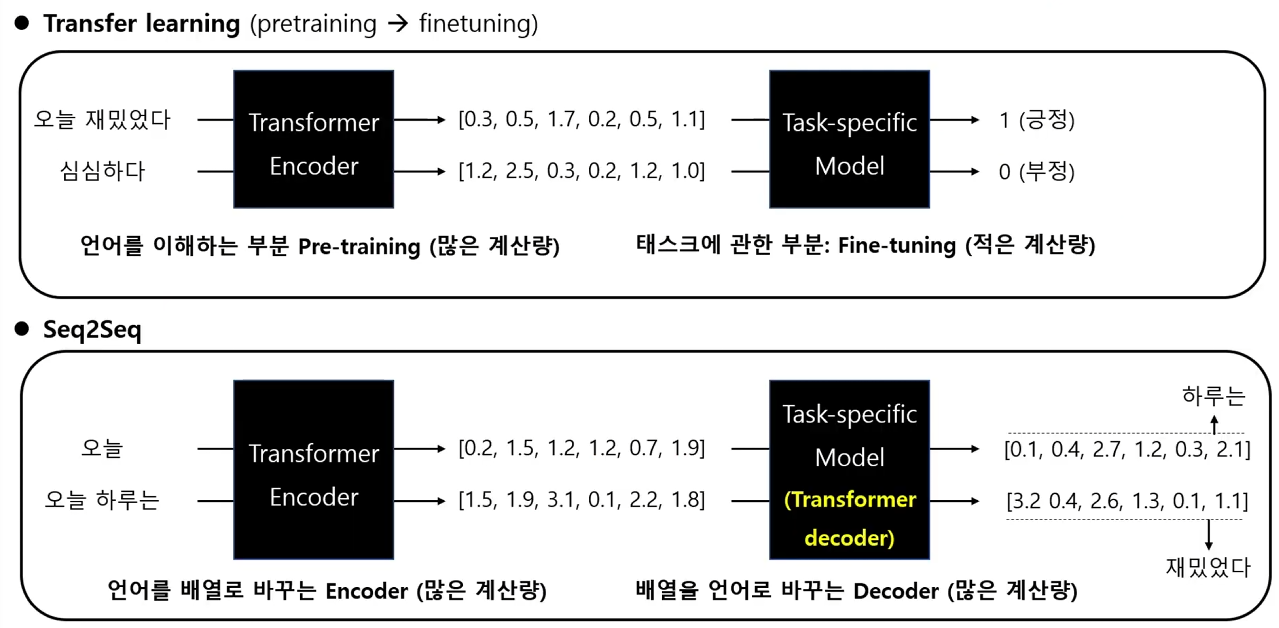
Transfer Learning


- Transfer learning: 미리 대량의 텍스트로 언어 모델을 한 번 학습해 두고(pre-training), 이 결과값에 관심있는 task에 적합한 모델을 붙여 다양한 문제를 푸는 모델을 만들어 보자 (fine-tuning)
- 언어를 이해하는 부분: Pre-training
- 개인용 GPU로는 너무 오랜 시간이 걸리며, 수십 개(최신 논문은 수천 개)의 GPU를 연결하거나, 구글 TPU을 사용하여 학습한다. 경험이 없다면 관련된 여러 변수를 테스트 해보는데도 비용이 많이든다(수 천만원 단위).
- 하지만 대부분의 경우 이렇게 pre-training된 언어 모델을 가져와 자신이 풀고 싶은 문제에 적용(fine-tuning)하는 것으로 충분하다.
- 다양한 pre-training 방법을 한국어에 적용하여 학습한 결과를 깃헙에 공유 (Bert, Albert, Electra, Gpt3 등).
- 태스크에 관한 부분: Fine-tuning
- Devlin et al. (2018) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Original Bert 논문에는 한 번의 pre-training으로 다음과 같은 4가지 형태의 fine-tuning이 가능함을 보임
- Sequence pair classification (문장 2개 관계 판단)
- Single Sentence Classification (문장 분류)
- Question Answering (질의응답)
- Single Sentence Tagging (개체 분석)

Autoencoding & Autoregressive

Application (Digital Marketing) 예시

Seq2Seq