DETR: End-to-End Object Detection with Transformers
GitHub Link: https://github.com/facebookresearch/detr
GitHub - facebookresearch/detr: End-to-End Object Detection with Transformers
End-to-End Object Detection with Transformers. Contribute to facebookresearch/detr development by creating an account on GitHub.
github.com
DETR: End-to-End Object Detection with Transformers 이 논문은 ECCV에서 2020년에 발표가 된 논문이다.
Facebook Research 팀에서 발표했다.
DETR은 기존의 객체 탐지(object detection) 기술과 비교했을 때 매우 간단하고, 경쟁력 있는 성능을 보인다.
이 논문에서 제안한 것
→ DETR (DEtection TRansformer)
1. 이분 매칭(bipartite matching) 손실 함수
2. Transformer

전체 구조를 자세하게 보면, 이미지의 특징(feature)을 추출하기 위해서 CNN Backbone Network를 사용했다.

그리고 이미지에서 각각의 상대적인 위치 정보를 담기 위해서 추가적으로 positional encoding을 추가해서 encoder로 데이터가 들어가게 된다.

그리고 positional encoding에서 각각의 픽셀 정보들은 각각의 sequential한 데이터로 분류가 되어서, sequential한 데이터를 처리하기 위해 적합한 transformer architecture로 들어가게 되고, 각각의 데이터들은 D라는 Dimension을 가지는 이미지 feature로서 구성이된다. 각각의 픽셀이 가지고 있는 이미지 feature 정보들이 sequentialy 처리가 되어서 encoder가 여러개의 각각의 layer를 거쳐서 encoding을 실행하고, decoder로 들어가게 된다.

decoder도 encoder와 마찬가지로 초기에 몇개의 object queries로 시작해서, query를 거쳐서 나온 결과가 각각 object에 대한 클래스와 object가 어디 존재하는지 bounding box의 위치를 알려줄 수 있도록 분류가 된다. 또한, 초록 박스를 보면 'no object'라고 물체가 존재하지 않는 곳이다.

그 후 탐지를 한 object detection 결과가 실제 값과 비교했을 때, 매칭이 성공적으로 이루어질 수 있도록 이분 매칭 함수까지 사용한다. 이러한 이분 매칭 함수를 통해서 중복되지 않은 인스턴스를 각각 탐지할 수 있도록 만들어준다.

연구 배경 (이 전 모델들의 문제점)
기존 객체 탐지(object detection) 방법들은 너무 복잡하며, 다양한 라이브러리를 활용한다.
(너무 많은 라이브러리를 사용하기 때문에 고려할 것이 많았음)
사전 지식(prior knowledge) 요구: bounding box의 형태, bounding box가 겹칠 때의 처리 방법, ...
→ 기존 방법은 사전 지식 요구를 많이함
예를 들어, 기차를 탐지한다고 하면 이미지에서 bounding box를 길게 설정해서 탐지하고자 하는 대상에 대한 사전 지식을 사용할 수 있었다.
NMS(Non-maximum Suppression)
하나의 이미지가 주어졌을 때 하나의 객체에 대해서 여러개의 bounding box를 그려넣음
(Neural Network가 이미지에서 물체가 존재할 법한 위치를 찾아서 여러개의 bounding box를 그림)
하지만, 이렇게 하다보면 중복되는 box가 많이 있을 것이다.
이제, 중복되는 box들을 압축해서 불필요한 것들은 box를 제거해서 각 객체마다 한개의 box가 나올 수 있도록 한다. → NMS

▶ 이전 모델들의 성능은 postprocessing (NMS, ancor, region proposal 등)에 크게 의존되었지만, DETR에서는 이러한 과정들을 없앴다. 이러한 과정들을 없애고, 새로 만든 방법은 transformer의 encoder-decoder 구조를 사용하였고, self-attention mechanism은 이 구조가 removing duplicate prediction과 같은 prediction의 제약을 다루기 쉽게 만들어줬다.
* removing duplicate prediction (중복 제거 예측)
주로 NMS와 같은 방법으로 예측된 object bbox가 중복되지 않도록 만들어주는 것이다
본 논문의 아이디어 1 (이분 매칭)
이분 매칭 (bipartite matching)을 통해 set prediction problem을 직접적으로(directly) 해결한다.
*set: 집합
집합의 특징 -- 중복되는 원소가 없음, 순서가 상관이 없음
예를 들어, 위의 강아지 고양이 사진에서 강아지와 고양이의 bounding box 순서가 바뀌어도 상관이 없다. 강아지가 어디에 존재하고, 고양이가 어디에 존재한다 이런식으로 해도 상관이 없음
이 전의 연구까지는 NMS를 이용하여 이미지에 각각의 instance가 존재할 법한 위치들을 region proposal을 해서 겹치는 것을 제거하는 과정들이 필요했지만, DETR에서는 set prediction problem으로 직접적으로 해결할 수 있다.
set of box predictions를 N으로 하고, 전체 N개 만큼만 이미지에 object instance가 존재할 수 있을거라는 것을 고정시켜버리면, 이 후로는 이분 매칭(bipartite)을 통해서 직접적으로(directly) 해결할 수 있다.

그 후 실제값과 예측값을 비교할 때 이분 매칭을 수행해서 하나씩 1대 1 매칭이 될 수 있도록 하게 한다.
(추가적으로, loss는 Hungarian algorithm을 기반으로 한 loss를 디자인해서 처리한다.)
만약, 전체에 6개object instance가 존재할 수 있다고 가정하면(어떤 이미지가 들어왔을 때 최대 6개까지만 탐색할 수 있다고 했을 때)
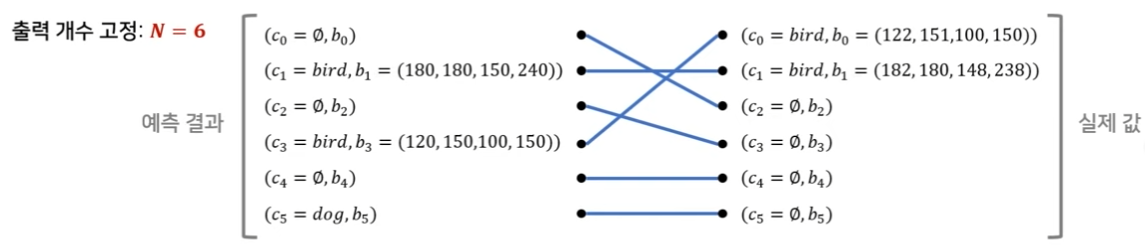
c0 - 객체가 아무것도 없다.
c1 - bird가 있고, bird의 바운딩박스 좌표는 (180, 180, 150, 240) -> (x, y, w, h)이다.
c3 - 객체가 아무것도 없다.
...
c5 - dog가 그 위치에 없을 경우 객체가 아무것도 없다고 판단한다.
클래스(bird, dog, ...)가 동일하고 bounding box 좌표(b)가 유사할 때 더 낮은 loss 값을 가지도록 matching loss값을 구성한다. 그런 다음, 그 loss값을 다 합했을 때 즉, 전체 matching이 끝났을 때 전체 loss값이 가장 줄어드는 방향으로 이분 매칭을 수행한다.
본 논문의 아이디어 2 (Transformer)
Transformer는 어떤 sequential한 데이터의 나열이 있을 때, 효과적으로 내재된 임베딩 같은 것들을 잘 학습할 수 있도록 하기 위해 사용할 수 있는 Arcitecture 중 하나이다.

Transformer(encoder-decoder)가 어떤 방법으로 사용되었는가?
- Attention을 통해 전체 이미지의 문맥 정보를 이해
- 이미지 내 각 인스턴스의 상호작용(interaction) 파악 용이
- 큰 bounding box에서의 거리가 먼 픽셀 간의 연관성 파악 용이
Encoder가 어떤 방법으로 사용되었는가?
- 이미지의 특징(feature) 정보를 포함하고 있는 각 픽셀 위치 데이터를 입력받아 인코딩 수행 (self-attention과 같은 과정을 통해서 이미지에 feature 정보가 들어왔다고 하면, self-attention을 수행하면서 각 픽셀에 대한 상호작용 및 연관성 정보를 학습할 수 있게함)
인코더(Encoder)는 d x HW 크기의 연속성을 띠는 feature map을 입력으로 받는다.
(이때, d는 image feature(자연어 처리에서는 embedding이라고 많이 부름)를 의미하고, HW는 각각의 픽셀 위치 정보를 담고 있음)
인코더의 self-attention map을 시각화 해보면 개별 인스턴스를 적절히 분리하는 것을 확인할 수 있다.
(이렇게 각각의 개별 인스턴스를 분리하면서 나중에서 서로 다른 인스턴스로서 객체를 detection 할 수 있음)

Decoder 가 어떤 방법으로 사용되었는가?
- N개의 object query를 초기 입력으로 받으며 인코딩 된 정보를 활용
- 각 object query는 이미지 내 서로 다른 고유한 인스턴스를 구별
N개의 object query(학습된 위치 임베딩)를 초기 입력으로 이용한다.
인코더가 global attention을 통해 인스턴스를 분리한 뒤에는 디코더는 각 인스턴스의 클래스와 경계선을 추출한다.
(decoder attention을 시각화했을 때 주로 attention이 물체의 말단에 집중되는 것을 확인할 수 있는데, encoder는 global attention을 통해 instance를 분리한다면, decoder는 class와 object boundaries를 찾기 위해 object의 말단을 catch 한다는 것을 알 수 있다.)

→ bounding box가 잘 만들어질 수 있도록 attention map을 사용한다.
Conclusion + Limiation
- Detection 뿐만 아니라 Segmentation task에서도 좋은 성능을 냈다.
- 기존의 모델들과 다르게 transformer bipartite matching loss를 통한 global information에 대해서 학습하여 좋은 성능을 동작 할 수 있다는 장점이 있다.
- 하지만, 작은 object에 대해서는 성능이 떨어지고 학습 시간과 자원이 많이 소요된다.
출처
[1] https://arxiv.org/pdf/2005.12872.pdf
[2] https://www.youtube.com/watch?v=hCWUTvVrG7E
[3] https://github.com/facebookresearch/detr
[4] https://talktato.tistory.com/16
[5] https://herbwood.tistory.com/26
[6] detr tutorial Github Link: https://github.com/thedeepreader/detr_tutorial/tree/master/detr